GW16168 USA-Made M.2 AI Accelerator | NXP Ara240 DNPU
USA-MADE M.2 AI ACCELERATOR WITH NXP's ARA240 DNPU FOR INDUSTRIAL EDGE AI
Add Dedicated AI Processing to Embedded Systems with 40 eTOPS of Neural Network Acceleration
Deploy high-performance, low-power AI inference at the edge with 40 eTOPS of acceleration, 16GB of onboard LPDDR4 and industrial-grade reliability, powered by NXP’s Ara240 Discrete NPU (DNPU). Purpose-built for Gateworks VeniceFLEX, Catalina, and other compatible M.2 M-Key 2280 platforms, the GW16168 enables real-time machine vision, LLM inference and intelligent automation without cloud dependency.
Built for extreme industrial environments, the GW16168 operates reliably across an industrial temperature range of -40°C to +85°C and is manufactured in the USA to ensure supply chain transparency, quality control and long-term availability. Its PCIe Gen 4 interface and single 3.3V power supply enable efficient integration into industrial single board computers and edge systems, accelerating time-to-market while maintaining system reliability.

| Key Product Features | |
|---|---|
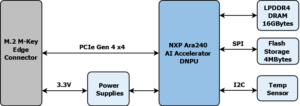
| Function: | Edge AI Acceleration (NXP Ara240 Discrete Neural Processing Unit DNPU) |
| AI Performance: | 40 equivalent Tera Operations Per Second (eTOPS) |
| Memory: | 16GB of LPDDR4 DRAM |
| Security: | Secure Boot and Root of Trust |
| Interface: | PCIe Gen4 (4x) signaling (compatible with PCIe Gen3 hosts) |
| Model Support: | Up to 16 billion parameters |
| Software: | Software Wiki |
| Supported Frameworks: | TensorFlow, PyTorch, ONNX |
| For Use With: | VeniceFLEX & Catalina Family of SBCs |
| Development Kit: | GW11062-1 |
| COO: | USA |
| Form Factor: | M.2 M-Key 2280 |
| Datasheet: | GW16168 Datasheet |
- Edge AI Accelerator
- Featuring NXP Ara240 Discrete Neural Processing Unit (DNPU)
- Enables real-time AI processing and decision-making
- Up to 40 equivalent Tera Operations Per Second (eTOPS)
- Exceptional performance per watt inferences
- AI-Model Frameworks Supported: TensorFlow, PyTorch, ONNX
- Security: Secure boot and root of trust
- Software SDK with extensible compiler for CNNs and LLMs
- M.2 2280 M-Key Form Factor with PCIe Gen4 (4x) Signaling
- 16GB of LPDDR4 DRAM for large model support
- Compatible with VeniceFLEX and Catalina SBCs
- -40°C to +85°C Operating Temperature
- Made in the USA
- 1 Year Warranty
USA-Made AI Accelerator for Embedded Edge AI Deployment
The GW16168 is a high-performance M.2 AI accelerator designed to add dedicated neural network processing to embedded and industrial systems. Powered by the NXP Ara240 Discrete Neural Processing Unit (DNPU), it delivers up to 40 eTOPS of AI inference performance, enabling real-time execution of machine vision, intelligent automation and generative AI workloads directly at the edge.
Equipped with 16GB of onboard LPDDR4 memory, the GW16168 operates independently of host system memory. It supports large neural networks, including Large Language Models and Vision Language Models up to 30 billion parameters using INT4 quantization. This enables advanced AI capability in power-constrained embedded systems without relying on cloud infrastructure.
The standard M.2 M-Key 2280 form factor and PCIe interface allow seamless integration with Gateworks VeniceFLEX, Catalina and other compatible platforms. Designed and manufactured in the USA and rated for industrial temperatures from -40°C to +85°C, the GW16168 provides a secure, reliable and long-lifecycle solution for deploying edge AI in industrial environments.
*Disclaimer: This product has only been tested on Gateworks Single Board Computers. Gateworks only provides support when used with Gateworks SBCs.

Made in the USA

40 eTOPS

Industrial Operating Temperature

10+ Years Product Lifecycle
Ara240 DNPU

Ruggedized for Shock & Vibe

Plug-And-Play with VeniceFLEX & Catalina SBCs
Linux Ubuntu BSP & Software Support
COMPATIBLE PRODUCTS
We recommend the following products designed to deliver robust performance, seamless connectivity and tailored functionality for a wide range of industrial IoT applications.

GW8100 VeniceFLEX SBC
✓ High-Performance Low Power ARM® SBC
✓ NXP™ i.MX 8M Plus CPU
✓ Linux OS & Board Support Package
✓ 1x Gigabit Ethernet Port
✓ 1x Flexible Socket
✓ Optional NXP™ Edgelock®SE052F: FIPS 140-3 Security Element

GW8200 VeniceFLEX SBC
✓ High-Performance Low Power ARM® SBC
✓ NXP™ i.MX 8M Plus CPU
✓ CE-Ready
✓ Linux OS & Board Support Package
✓ Isolated CAN & PoE
✓ 2x Gigabit Ethernet Ports
✓ 2x Flexible Sockets

GW9200 CATALINA SBC
✓ High-Performance Low Power ARM® SBC
✓ NXP™ i.MX 95 CPU
✓ NXP™ eIQ® Neutron NPU (Neural Processing Unit)
✓ Linux OS & Board Support Package
✓ 1x 10GbE Ethernet Port with TSN
✓ 2x Gigabit Ethernet Port
✓ 2x Flexible Sockets
✓ Optional NXP™ Edgelock®SE052F: FIPS 140-3 Security Element

GW9400 CATALINA SBC
✓ High-Performance Low Power ARM® SBC
✓ NXP™ i.MX 95 CPU
✓ Linux OS and Board Support Package
✓ NXP™ eIQ® Neutron NPU (Neural Processing Unit)
✓ 1x Gigabit Ethernet Ports
✓ 4x Flexible Sockets
✓ Optional NXP™ Edgelock®SE052F: FIPS 140-3 Security Element
Frequently Asked Questions (FAQs)
WHAT IS THE GW16168 AI ACCELERATOR?
The GW16168 is a USA-manufactured M.2 AI accelerator powered by the NXP Ara240 processor that provides up to 40 eTOPS of dedicated neural network inference performance for embedded systems.
WHAT TYPES OF AI WORKLOADS CAN THE GW16168 RUN?
The GW16168 supports a wide range of AI workloads, including:
- Large Language Models (LLMs)
- Vision Language Models (VLMs)
- Machine vision and object detection
- Robotics and automation
- Predictive maintenance
- Intelligent video analytics
WHAT TEMPERATURE RANGE DOES THE GW16168 SUPPORT?
The GW16168 and all of Gateworks' SBCs and accessories are rated for industrial-grade operation from –40°C to +85°C.
WHAT IS THE MAXIMUM MODEL SIZE SUPPORTED?
The GW16168 supports AI models up to 16 billion parameters, enabled by its 16GB onboard LPDDR4 memory.
WHAT SYSTEMS ARE THE GW16168 COMPATIBLE WITH?
The GW16168 is compatible with:
- Gateworks VeniceFLEX SBCs
- Gateworks Catalina SBCs
Additional compatible systems may include single board computers based on NXP Semiconductors' i.MX8MP or i.MX95 CPU with an M.2 M-Key 2280 slot.
WHICH AI FRAMEWORKS ARE SUPPORTED?
Supported AI frameworks include:
- TensorFlow
- PyTorch
- ONNX
These frameworks allow developers to deploy and optimize existing AI models efficiently.
WHAT IS THE EXPECTED LIFETIME AND AVAILABILITY?
Gateworks selects components with 10+ to 15+ year availability. As part of our lifecycle policy, we notify customers early about potential end-of-life events and offer inventory or continuity programs. Learn more about our EOL policy here.
WHAT IS EDGE AI AND WHY WOULD I RUN IT ON AN INDUSTRIAL SBC?
Edge AI means running AI/ML models locally on the device, close to sensors and actuators, instead of in a remote data center. Running AI on an industrial SBC reduces latency, improves reliability when connectivity is intermittent, keeps sensitive data on-premises, and lowers bandwidth and cloud costs. This is ideal for smart factories, robotics/AMRs, energy systems and remote monitoring, where real-time decisions matter.